Web Scraping JSON Data and Images from HTML: Python Tutorial 📖


Hello Python developers.
Not Java this time, if you're looking for Java tutorials, you can find them here.
A quick, perhaps boring, story: I began my programming journey with Python back in the days when it was less of a popular. Its simple syntax and easy setup for the development environment were what attracted me to it initially.
However, like many developers, I ventured away, exploring Java and JavaScript. But here's the irony – now I find myself gravitating back towards Python, appreciating its elegance and simplicity once again.
In this tutorial, I'm using Python to do a simple task – extracting books information and their images from a website.
This process, known as web scraping, is a tool for extracting data from websites. We'll dive into how you can scrape JSON data and images from HTML pages, transforming the web into a rich source of information for your projects.
Understanding the Basics
Before jumping into the code, let's understand what web scraping involves. Essentially, web scraping is the process of programmatically accessing a web page and extracting specific data from it.
Web scraping, in this context, involves accessing a web page, extracting the necessary data from it, and then structuring this data into a JSON format. We'll focus on:
- Parsing HTML Data: Identifying and extracting the necessary data from a webpage.
- Generating JSON Files: Organizing the extracted data into a structured JSON format.
- Fetching images and resizing them (Optional): We will download the products images and resize them to be lightweight
Essential Python Tools for Web Scraping
Python shines with its range of libraries that simplify web scraping. For this task, we'll use:
requests: To fetch content from the web.BeautifulSoupfrombs4: For parsing HTML and navigating the DOM tree.ImagefromPIL: To handle image processing tasks.BytesIOfromio,json,os,time,datetime(buildin): For various utility functions.
Let's start
For the sake of this tutorial we will do a webscraping for this page https://www.camelcodes.net/books/

We will fetch the products in the page, generate a json file with the data, extract images and save them.
What you will need ? A text editor and Python 3 installed.
Folder structure: After running the script we will have a folder structure like this
/ (root)
├── main.py -- Our script file where everything is happening
├── requirements.txt -- Dependency listing
└── generated/ -- Where we store the scraped data
├── images/
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── image3.jpg
│ ... (other images)
│
└── json/
└── data.json
Let's start with the requirements.txtfile
beautifulsoup4==4.12.3
pillow==10.2.0
requests==2.31.0After creating the requirements.txt file we need to install the dependencies.
Install the dependencies using PIP:
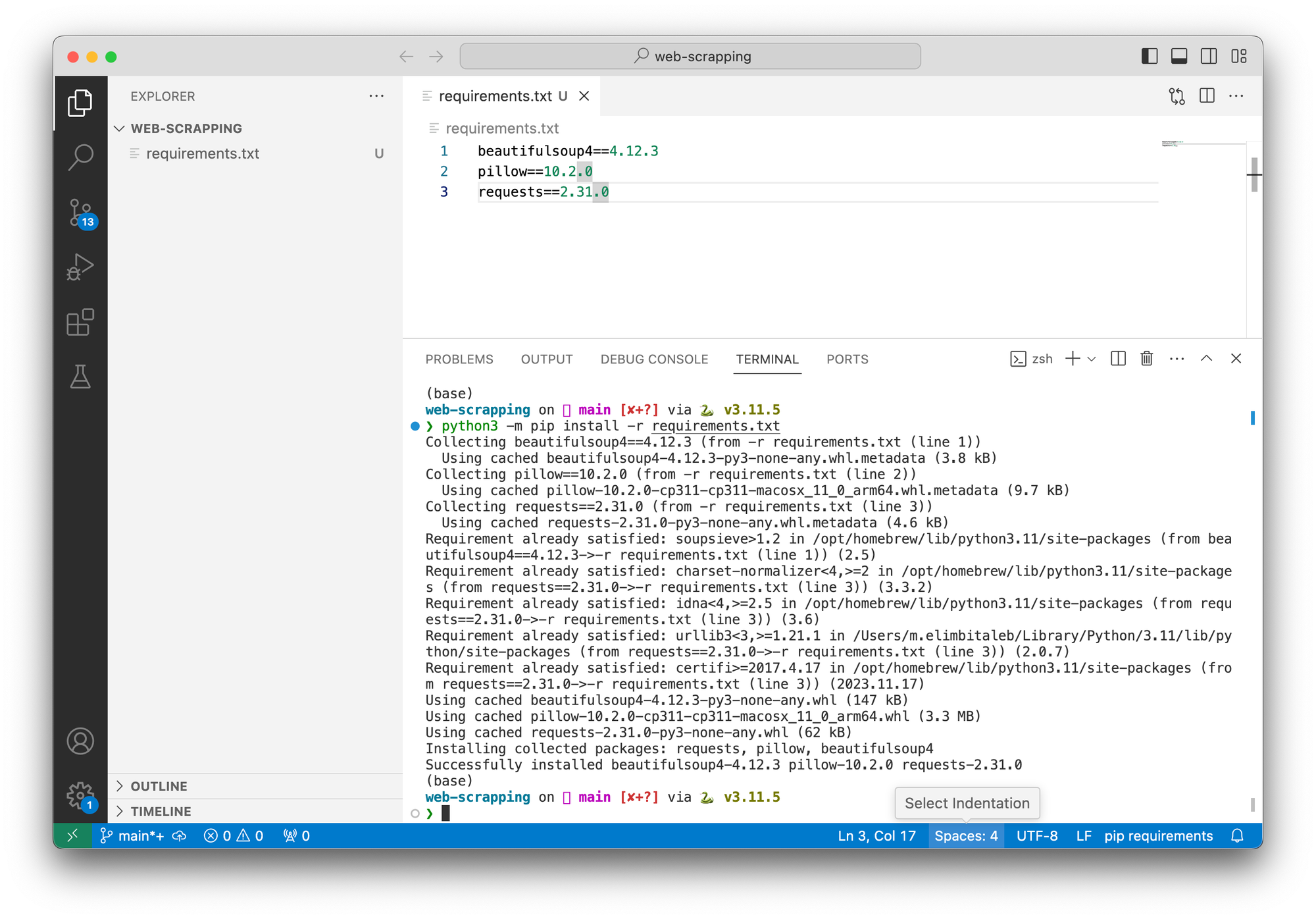
Open a terminal from your current working directory and run the following command.
python3 -m pip install -r requirements.txtThe output should be something like this
Once you have the needed dependencies, you can write the code.
We wil create a main.py script where we will have everything.
The script is designed to :
- Scrape book data from "https://www.camelcodes.net/books/", which lists various books along with their details.
- Resize images associated with the books as thumbnails.
- Save the data in JSON format for easy access and manipulation.
Functions used:
create_folder_if_not_exists: Ensures the required directories exist.save_json_file: Saves the scraped data into a JSON file.fetch_and_resize_image: Downloads, resizes, and saves images from URLs.main: The main function that orchestrates the web scraping process.
Workflow:
- Initialization: We start by creating necessary folders for JSON and image storage.
- Fetching Web Page: We fetch the HTML content of the target URL.
- Parsing HTML: Using BeautifulSoup, we parse the HTML to extract book data.
- Data Extraction: For each book, details like title, rating, description, image URL, and purchase link are extracted.
- Image Processing: Each book's image is downloaded, resized, and saved locally.
- Data Aggregation and Storage: All extracted data, along with the path to the resized image, are stored in a JSON file.
- Performance Logging: We then log the key actions and the total time taken for execution.
Show me the code 🤓
import requests
from bs4 import BeautifulSoup
from PIL import Image
from io import BytesIO
import time
import json
import os
from datetime import datetime
# Directory paths for saving JSON and image files
json_folder_path = "./generated/json/"
images_folder_path = "./generated/images/"
# URL to scrape
url = "https://www.camelcodes.net/books/"
def create_folder_if_not_exists(folder_path):
"""Create a folder if it does not exist."""
if not os.path.exists(folder_path):
os.makedirs(folder_path)
def save_json_file(scraped_data):
"""Save the scraped data to a JSON file."""
with open(os.path.join(json_folder_path, 'data.json'), 'w') as json_file:
json.dump(scraped_data, json_file, indent=4)
print("Data saved to JSON file data.json")
def fetch_and_resize_image(image_url):
"""Fetch an image from a URL, resize it, and save it locally."""
response = requests.get(image_url)
image_data = response.content
image = Image.open(BytesIO(image_data))
image.thumbnail((400, 300))
file_name = os.path.basename(image_url)
file_path = os.path.join(images_folder_path, file_name)
image.save(file_path, format="jpeg")
return file_name
def main():
"""Main function to scrape book data and save it."""
start_time = time.time()
# Create necessary folders
create_folder_if_not_exists(json_folder_path)
create_folder_if_not_exists(images_folder_path)
# Fetch HTML content from the URL
print(f'Downloading html page: {url} ...')
response = requests.get(url)
html = response.content
# Parse HTML using BeautifulSoup
print('Parsing HTML file ...')
soup = BeautifulSoup(html, 'html.parser')
books = soup.find_all('div', class_='kg-product-card-container')
# List to store scraped book data
scraped_data = []
# Iterate over each book and extract data
for book in books:
title_tag = book.find('h4', class_='kg-product-card-title')
title = title_tag.text.strip() if title_tag else 'No Title'
rating_stars = book.find_all('span', class_='kg-product-card-rating-star')
rating_stars_active = book.find_all('span', class_='kg-product-card-rating-active')
rating = f"{len(rating_stars_active)}/{len(rating_stars)}"
description_tag = book.find('div', class_='kg-product-card-description')
description = description_tag.text.strip() if description_tag else 'No Description'
image_tag = book.find('img', class_='kg-product-card-image')
original_image_url = image_tag['src'] if image_tag and 'src' in image_tag.attrs else ''
buy_link_tag = book.find('a', class_='kg-product-card-button', href=True)
buy_link = buy_link_tag['href'] if buy_link_tag else ''
print(f'Fetching and resizing image {os.path.basename(original_image_url)} ...')
thumbnail = fetch_and_resize_image(original_image_url)
# Append book data to the list
scraped_data.append({
'title': title,
'rating': rating,
'description': description,
'original_image_url': original_image_url,
'thumbnail_image': thumbnail,
'buy_link': buy_link,
'last_update_date': datetime.now().isoformat()
})
# Save scraped data to JSON
print('Writing JSON file ...')
save_json_file(scraped_data)
# Calculate and print elapsed time
elapsed_time = time.time() - start_time
print(f"Took: {elapsed_time:.2f} seconds")
if __name__ == '__main__':
print('Booting up...')
main()
How to run run my python the script ?
Running a python script is as easy as:
python3 main.pyThe output log will be something like this
Booting up...
Downloading html page: https://www.camelcodes.net/books/ ...
Parsing HTML file ...
Fetching and resizing image 81sdcxLtlwL._SY522_.jpg ...
Fetching and resizing image 61r4tYVsRVL._SY522_.jpg ...
Fetching and resizing image 71rQMKhj-ZL._SY522_.jpg ...
Writing JSON file ...
Data saved to JSON file data.json
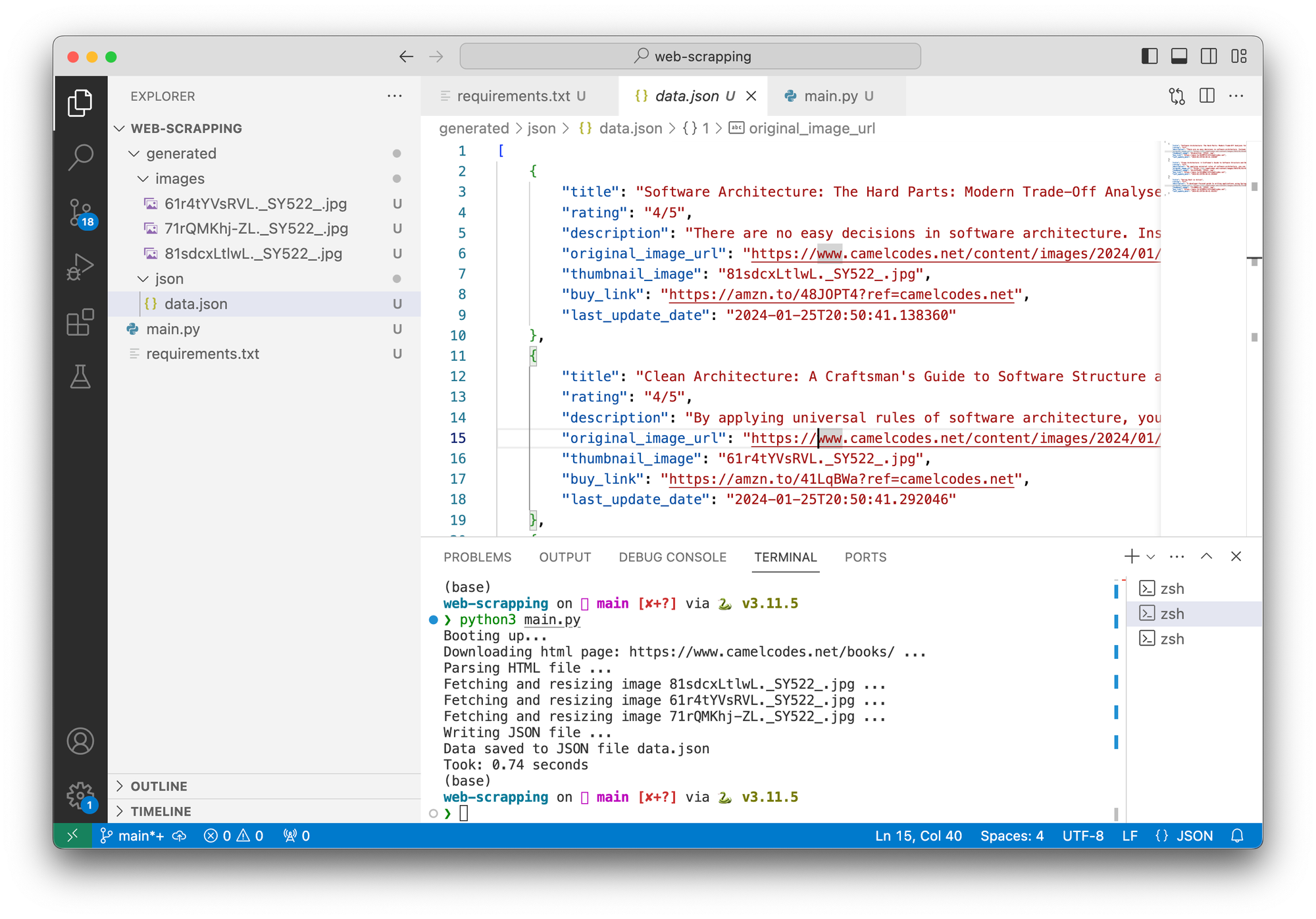
Took: 0.74 secondsThe generated data.jsonfile should contain something like this
[
{
"title": "Software Architecture...",
"rating": "4/5",
"description": "There are no easy decisions in software...",
"original_image_url": "https://www.camelcodes.net/..Y522_.jpg",
"thumbnail_image": "81sdcxLtlwL._SY522_.jpg",
"buy_link": "https://amzn.to/48JOPT4?ref=camelcodes.net",
"last_update_date": "2024-01-25T20:50:41.138360"
},
{
"title": "Clean Architecture: A Craft...",
"rating": "4/5",
"description": "By applying universal rules...",
"original_image_url": "https://www.camelcodes.net/c..SY522_.jpg",
"thumbnail_image": "61r4tYVsRVL._SY522_.jpg",
"buy_link": "https://amzn.to/41LqBWa?ref=camelcodes.net",
"last_update_date": "2024-01-25T20:50:41.292046"
},
{
"title": "Spring Boot in Action",
"rating": "4/5",
"description": "A developer-focused g...",
"original_image_url": "https://www.camelcodes.net/content/images/2024/01/71rQMKhj-ZL._SY522_.jpg",
"thumbnail_image": "71rQMKhj-ZL._SY522_.jpg",
"buy_link": "https://amzn.to/423dKPn?ref=camelcodes.net",
"last_update_date": "2024-01-25T20:50:41.452351"
}
]
That was it for today's tutorial.
If you want me to write about a specific subject just drop a comment or ping me on LinkedIn.
Source code
On Github as always: https://github.com/camelcodes/web-scraping-python-beautifulsoup-image-processing-html
 camelcodes
camelcodesHappy coding ❤️